
ALGORITHMIC CONSENSUS
A Survey of Blockchains as Decentralised, Distributed Computer Networks Maintained by Algorithms

Cryptocurrencies won’t exist without blockchain technology and Satoshi's innovative work with the Nakamoto protocol. Blockchains are basically a form of distributed ledger technology (DLT or replicated journal technology or RJT). What are these things and how do they even work!? Are all these abbreviations just word salad to cover up the fact that we possess almost no rizz?
Read on for a top-down overview of this innovative technology with a primary focus on their consensus mechanisms. It's glossed over at some points with sparse details but it's intro level so allow it! Enjoy lads☕
Distributed Ledger Technology
is just big words for a system used to share data to different nodes in a network.
DLT is a system/protocol of replicated digital data spread across participating systems in a network (often regardless of geographical constraints) at the same time and in the absence of a single point of failure wrt hardware. They are essentially p2p networks run on consensus algorithms to ensure full replication of information in timely order with minimal human interference in process flow.
Replication and update of network state occurs independently across participating systems and consensus is reached among participants over the correctness of a network value through preset models of a correct majority/honest minority.
DLTs may be permissioned or permissionless as regards to who can cause network state updates.
Permissioned DLTs are censored and require approval from a known administrator before a new node can join or for existing nodes to be able to read or write to the network. Thus security in such networks is assured due to the presence of the admin. examples of such networks include supply chains and bank chains.
Permissionless DLTs are open to ~anyone~ who wishes to join regardless of location and identity. However, entry and participation is gated and governed by preset algorithms which permit pseudonymity and decentralisation but incur cost functions in order to ensure network security. They are secured by cryptographic keys, cost & hash functions and game theory assumptions in different iterations. The most prominent examples of such networks are cryptocurrencies.
Permissionless DLTs wrt cryptocurrencies can be structured in two forms
blockchains
directed acyclic graphs.
BLOCKCHAINS:
are a form of message replication systems composed of various subsystems which cooperate to ensure its assumed features are maintained. Data contextually called transactions are stored in "blocks" on a decentralised database managed by participants in a p2p network overlayed on the internet. These networks are upheld by nodes/peers acting within the confines of different sets of protocols which govern the various subsystems of the network.
The subsystems present in a blockchain depend on its intended usecase and make up its architecture. Based on their architecture, blockchains can be classified into
monolithic blockchain stacks which contain all the necessary subsystems for them to function properly independently.
modular blockchain stacks which outsource at least one subsystem necessary for proper functioning to another blockchain system.
The subsystems/aspects/layers present in a typical monolithic blockchain are
The network layer which is composed of a peering protocol and consensus protocol. It governs how nodes communicate with each other and how they are to reach uniform decisions independently both in the presence and absence of faults which threaten the network.
The data (availability) layer which is responsible for maintaining a properly structured, network-validity-rules-conformant ledger of transactions and blocks which is replicated across participating nodes in the network.
The execution layer which is responsible for connecting end-user applications built atop the blockchain to the data layer and executing app-specific commands.
In modular blockchains, an extra subsystem known as the settlement layer is part of its stack and is responsible for providing the blockchain with an alternate execution layer (oversimplified and glossed over i know) among other functions.
Blocks are the vessels of data contained in blockchains, they are serially linked to each other to form the block-chain. They are denoted with a "header" which contains three distinct parts
The hash of the previous block which basically serves as the link between any two blocks and is present in all blocks except the genesis block.
The block's hash which contains the timestamp, nonce and difficulty i.e it contains the conditions under which the block was formed, and
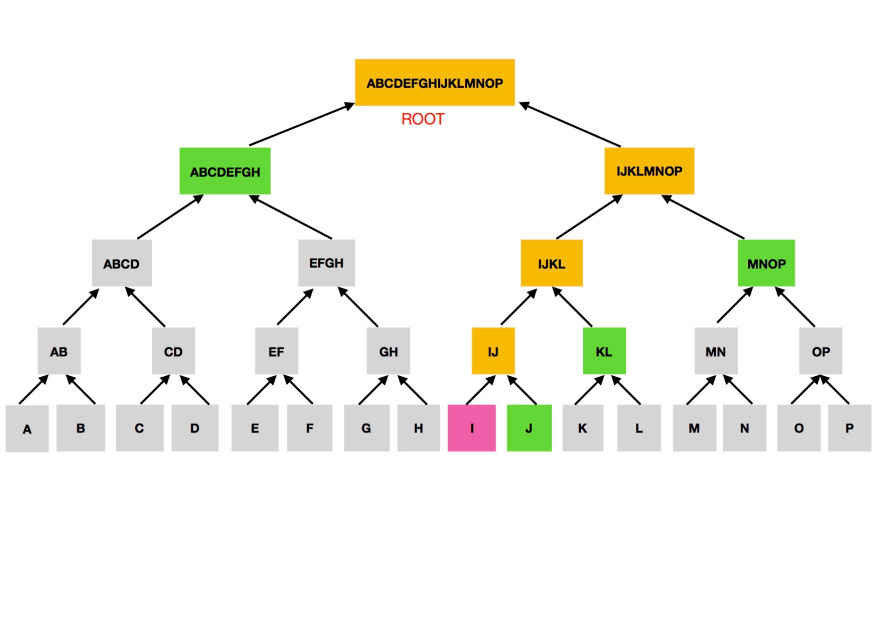
The merkle tree, represented by the merkle root hash which is a summary of all the transactions contained in a block.
Merkle trees are data verification structures which use hash functions (commonly SHA256) to pair data in order to prevent obfuscation and crowding while maintaining provable integrity. They contain three parts
leaf nodes which are the transaction hashes (txid) of each transaction contained in a block, they contain the details of a transaction.
non-leaf (branch) nodes which typically begin as the hash value of two previous leaf nodes ie two previous transaction hashes are hashed together to produce a non-leaf node. This process is repeated for every transaction in a block and resulting non-leaf nodes till there's only two hash values left.
merkle root/root hash which is the hash of the last two non-leaf node values. it is a unique hash for all the transactions contained in a block and can be used to identify and verify txids.
DIRECTED ACYCLIC GRAPH:
abbreviated DAG aka acyclic diagraph is a directed graph with no cycles. They typically display assumptions about the relationship among multiple data items (contextually known as vertices), these assumptions are in the form of directed lines (←/→) from one vertex to another and are knowns as edges or arcs. Therefore a DAG can be said to be a data modelling tool with two components; vertices which are related data items and edges which show the directional relationship between vertices, connecting them in a non-binary direction so that no vertex can reach itself via a nontrivial path.
A simple example of a DAG is a family tree in the absence of pedigree collapse. Since no one can be their own ancestors, a vertex can represent each family member and edges show parent-child relationships.
In the context of consensus in decentralised networks, DAGs although not a very popular choice are theoretically (so far) more efficient, scalable and cheaper relative to blockchains if you're willing to ignore the centralisation risk. In this case, vertices are transactions which must be built atop preceding, valid but unconfirmed transactions (known as tips) via a chosen algorithm which leads to confirmation of linked transactions and prevents network spamming while availing the new transaction for confirmation by a succeeding transaction. This process continues in an infinite cycle. There are various generic algorithms for tip/parent selection, these include
The uniform random tip selection in which incoming transactions pick at least two random tips to confirm and build on. Seems so simple and elegant but transaction rate isn't constant and as such can cause tips to be ignored for longer than usual.
When transaction rates are too high ie the network is busier than usual, incoming transactions are likely to link directly to the genesis transaction and ignore each other and other pre-existing tips. When transaction rates are too low, "chains" occur where incoming transactions build on only one tip instead of multiple and hence resemble a blockchain.
The unweighted random walk tip selection scheme in which a "walker" algorithm is implemented from genesis whose function is to "point" incoming transactions to tips which they are to build on with an equally weighted probability of selection for each existing tip. The weight of a transactions refers to how many other transactions are built on it either directly or indirectly.
This scheme is plagued by lazy tips. Lazy tips are tips which build on previously confirmed transactions rather than recent ones causing the ledger to remain relatively stale .
The weighted random walk scheme which maintains most properties of the unweighted scheme but considers the weight of tips in order to disincentivise creation of and building on lazy tips while maintaining the random walk property to prevent "super-weighted" walks in which incoming transactions only build on the heaviest available tip leading to many unapproved and ignored tips.
FAULT TOLERANCE IN DISTRIBUTED NETWORKS AND THE NETWORK LAYER
In a typical distributed network, clients issue operation requests to a network of nodes which are supposed to provide timely and correct responses to them regardless of individual node failure. To achieve consensus on response values, a collection of nodes -which can communicate with each other- individually draw a specific value from a set of values and all correct/honest nodes must arrive at the same final value independently for every given initial value. This process is governed by a set of rules enshrined in a peering protocol for communication and consensus protocol for agreement collectively known as a consensus mechanism or an atomic broadcast protocol.
The need for peering/consensus protocols in distributed systems originates from the need to provide failure resilience across multiple nodes which hold ledger replicas. Thus the major goal of a consensus mechanism is to ensure that all participants maintain the same distributed ledger while implicitly guaranteeing the fault tolerance and security of such networks.
Consensus protocols aren't implemented to prevent bad actors per say, they only broadcast consistency ie all components must receive the same message and you're home free. Hence consensus in this context mostly refers to agreement of majority non-faulty nodes on a single value whether adversarial or good. Validity rules in a consensus protocol are therefore said to be deterministic and uniform across all nodes such that individual nodes do not have the power to propose what constitutes a valid message.
Generic properties of a consensus protocol include;
Liveness ie requests/messages from correct clients(network users) must eventually be processed. Such requests must be valid(broadcasts from nodes must eventually be ordered according to the consensus) and all honest nodes must be in agreement over message values.
Consistency ie when an honest node decides on the correctness of a value, all other honest nodes must come to the same decision. Consistent systems must guarantee integrity(message delivery must occur only once) and total order(all honest nodes must extract the same order for all delivered messages).
Tradeoffs are made between these two properties in distributed networks in order to tolerate temporary partitions/forks without causing network failure.
Consensus protocols contain communication and failure processes for participating nodes which govern how they are to function in normal conditions and in case of a fault.
Communication processes can be synchronous, partially synchronous or asynchronous.
Failure processes can be crash fail or byzantine fail models.
Network synchrony is the level of coordination existing among all processes of a network; it can also refer to how nodes communicate with each other and the network. There are three forms of network synchrony
synchronous networks in which process completion is constantly coordinated to occur within a stipulated time constraint. ie message delivery amongst participant nodes is guaranteed within a known fixed delay.
partially synchronous networks wherein processes are loosely coordinated with an approximately common notion of time causing guaranteed message delivery after an undefined delay ie delivery time is variable as delivery is certain. There are two forms of partially synchronous networks
•weak synchronous networks which require that time of message delivery in network decreases as more time elapses indefinitely ie fixed bounds exist on message delivery time but are only known a posteriori.
•eventual synchronous networks which ensure message delivery on fixed delay after an undefined amount of time has elapsed ie fixed bounds exist on message delivery but are only guaranteed to start holding after some unknown time has elapsed.
On an adequate time horizon, processes of partially synchronous networks play out similarly to processes of synchronous networks.
Asynchronous networks wherein there is little to no coordination of processes and no delay guarantees on message delivery due to the absence of a shared notion of time. In such networks, consensus can hardly be guaranteed in the event of a single fault within the network. this is known as the "FLP impossibility" and is usually overcome by randomised decision making and relaxed/probabilistic process termination.
Faults/failures can arise in nodes of distributed systems in different forms affecting the network's resilience to attacks and causing abnormalities. It is a peculiar case because in such networks, each node is regarded as both a server and a client as opposed to traditional architecture. Faults may be:
Crash faults which occur when nodes execute protocol instructions correctly but can stop at any time and never restart. It mostly occurs due to denial of service attacks or sudden power shutdowns.
Byzantine faults which cause arbitrary, malicious behaviour in nodes and are generally the most important to circumvent as toleration of byzantine faults implies toleration of crash faults. It is mostly caused by adversarial influence on either hardware or software.
Peering protocols and Information Propagation in Distributed Networks:
As previously inferred, data stored on distributed networks don't have a particular "source" that is responsible for ensuring data validity and integrity, instead this function is handled by all nodes that maintain a replicated state of the chain.
Peers/nodes in a typical blockchain network can assume two major roles as regards to transaction validation and state transitions
Block producing/ master nodes aka miners(stakers) who are responsible for ensuring that requests from network users fit within the validity constraints of the blockchain. if so, they approve such requests and put it together with other valid requests in block which is gossiped to other block producing and qualified non-block producing nodes who recheck its validity. Consensus nodes can prevent malicious behaviour by ignoring/censoring invalid transactions and blocks.
Non-block producing nodes; other network users who are also divided into two further groups
1. Full nodes aka validators who possess a local replicated network state. They are generally responsible for aggregating and disseminating transactions and blocks in the network. They can perform every other function as miners but cannot produce blocks. They propagate only the valid state of a blockchain and hence can counter malicious behaviour of block producers by ignoring invalid state transitions.
2. Light/Client nodes who are only able to read limited data items on a blockchain (block headers and a few transactions in most cases) and hence cannot fully participate in network validation processes.
Multiple participating nodes contribute different parts of the story (transactions from different clients) to each other to form a shared full picture. The process is referred to as epidemiological gossiping as all components of the network are potential disseminators of messages and data. Each eligible component randomly chooses a subset of its peers and repeatedly forwards new data to them till a predefined condition is satisfied.
Gossiping in distributed systems refers to the repeated probabilistic exchange of data between multiple network peers. It is the endless process of randomly selecting other members of a network and continuously exchanging network updates amongst each other in form of data sets.
Gossip protocols are useful in aggregation of different data subsets located at disparate nodes in a network. Data dissemination, aggregation and querying is performed by every qualified non-faulty network node resulting in a shared common state across the network.
Gossip protocols can be based on any of the following generic models
The infect-and-die model in which nodes which obtain new messages in the network share it with a subset of its peers only once and stays silent till new messages are introduced again.
The infect forever model in which nodes continuously forward a new message in the network to their peers repetitively until some stoppage criteria is satisfied.
Gossip protocols are generally made up of three components that can be customised to network fit
a) Peer selection: nodes must select other nodes to connect and share data with. different protocols assume different peer sampling services to allow nodes select from a pool of other nodes uniformly in a random manner.
b) Data exchange: this component dictates what type of data nodes can share with their peers. Typically, nodes in a blockchain network share application data (transactions and network state) but they can also share references to other nodes they are paired with hence, enhancing network distribution and topology.
c) Data processing: this governs what a node does with received data. Generally, nodes update their local state and rebroadcast the data to other nodes; in special cases, they can also create new connections with other peers in the network.
Generic Consensus Protocols and Byzantine Fault Tolerant Implementations:
A Byzantine fault is an interactive inconsistency condition in a network of distributed computing systems where there is probability of failure or disinformation within components which can potentially affect the entire network. It was popularised by the Byzantine generals allegory which tells the story of five army generals who lay siege on a town and must attack or retreat together at any instant to ensure victory. However, they are in different locations and cannot communicate their plans directly (life without wifi sucks fr) and so they make use of relatively trustworthy messengers. This presents various risk vectors broadly summarised as
•maliciousness of individual generals
•maliciousness of messengers
Mapping this allegory into distributed networks, the generals are the nodes and the messenger(s) is a uniform communication model. Byzantine faults typically present different symptoms to various observers ie a byzantine node may appear live to a subset of its peers while it appears dead to another subset.
Byzantine fault tolerance is a predefined property of a distributed network which allows it to prevent/recover from byzantine faults and failures; it is mostly in the form of a consensus mechanism which contains communication and failure models for nodes in a network. Byzantine fault tolerant networks are implicitly crash fault tolerant.
Consensus mechanisms for permissionless blockchains are typically made up of various components;
1. block proposal/production system- this dictates how blocks should be generated and how verifiable validity proofs should be attached to prevent network spamming. block proposal schemes include proof of work, proof of stake, proof of authority etc.
2. information/block propagation- which dictates how valid blocks and their contents are to be broadcasted to other network participants. eg multicasting and gossiping schemes
3. block validation- this scheme is responsible for verification of block generation proofs and ensuring validity of network messages
4. block finalisation- this component decides how network participants are to agree in the presence of multiple correct but conflicting outcomes. eg GHOST, longest chain rule, byzantine agreements etc.
5. Incentive mechanism- a very important component of distributed networks used to ensure honest participation amongst participants and emit network tokens.
Block production is usually led by a single consensus node or a committee of consensus nodes per block epoch. These leaders are rewarded to parse a block and gossip it to other qualified nodes for validation. Epoch block producers are established via two techniques
A. Lottery techniques in which epoch leaders are selected based on luck and probability. Protocols that make use of this technique re referred to as "proof of resource" protocols due to their innate requirement that a node should spend a considerable amount of an (in most cases) external relatively scarce and costly resource in order to emerge epoch leaders. most PoR protocols are based off the nakamoto protocol as implemented in bitcoin and hence can only guarantee probabilistic finality of ledger entries. Examples of such protocols include proof of work, proof of retrievability, proof of burn etc.
Proof of Work: was first proposed as a cryptographic proof to prevent network spamming in 1993, it does this by proving to others that a certain threshold of verifiable computational effort has been expended in an attempt to send a message over the network. It was popularised as a consensus model for permissionless decentralised networks by Satoshi through its implementation in bitcoin which combined three core features
- a peer to peer network frame
- a cryptographically secure data ledger structure
- pow requirements to legitimise entries to a common ledger
PoW systems are typically energy intensive with the energy consumption considerably wasteful as it only validates consensus ie PoW algorithm doesn't care about computational puzzle outcomes, they serve to deter data manipulation by increasing costs so that it is practically infeasible but theoretically possible. The computational effort expended on a proof is often proportional to the probability of success. However, it is also possible to get lucky and obtain a solution to the cryptographic puzzle with relatively less effort. Verifying the solution to a PoW puzzle is as easy as it is hard to solve it.
• Nakamoto consensus protocol- aka "proof of work" is basically a summation of what makes bitcoin work. it is a form of solution-verification PoW protocol wherein blocks are proposed by a proof of work mechanism with intensive hash functions set such that the hash result satisfies a difficulty target which is algorithmically adjusted to maintain a preset block interval. mined blocks are propagated via advertisement based gossiping.
When a new block is received and validated, a node advertises it to its peers who put in request for said block as an extension of their local copy of the ledger. This process continues till the block is obtained by all non-faulty nodes.
Block validation is governed by the infamous rule that blocks and their contents must be validated before and during broadcast to peer nodes and before appendage to the blockchain. Validity checks include double spend checks and block header PoW validity check.
Block finalisation is governed by the "longest chain rule" which states that mining should always extend the longest existing chain. In practice, the chain with the most accumulated proof is extended as it is possible to accumulate more proof and be shorter.
Incentives are granted to nodes whose blocks are deemed valid in the form of coinbase transactions to oneself and block transaction fees.
The nakamoto protocol is probabilistically final like every other PoR protocol.
Probabilistic finality is the idea that a previously accepted block and its contents may still be discarded by the network but with an exponentially diminishing probability as the blockchain size increases. As result of this feature, this protocol can only achieve eventual double-spend resistance. It also helps the protocol circumvent the >⅓ faulty nodes bft threshold allowing conflicting outcomes as blockchain forks as long as they'll be eventually trimmed by the honest majority.
B. Voting techniques in which eligible network participants vote to select epoch block producers based on their stake in the network. This stake is mostly in the form of locked up network tokens over a stipulated period. Such techniques are generally less stressful and power-intensive.
There are two major forms of voting based protocols- BFT protocols and PoS protocols.
Byzantine Fault Tolerant protocols are voting-based consensus protocols that utilize byzantine agreements and state machine replication to achieve consensus in blockchain networks. Classical BFT implementations are best suited for permissioned and semi-permissioned blockchains. Examples of BFT protocols include pBFT and rBFT.
• Practical Byzantine Fault Tolerant protocol abbreviated pBFT, makes use of cryptographic algorithms(hashes, signatures etc) to ensure that for every 3f+1 nodes in a decentralised network where f is the number of nodes in the network and all nodes possess the same weight, consensus can be achieved when at least 2f+1 nodes are functioning properly. This is based off the majority rule as once one of two or more outcomes has lead on others, the other nodes must execute on the leading process regardless of previous stance.
The process of consensus in pBFT systems is shared across two nodes/roles
a) primary nodes which are responsible for transaction serialisation, block proposal, propagation and finalisation. Each consensus process has only one such node.
b) replica nodes which receive gossiped blocks, validate them by voting and participate in finalisation.
Client nodes are initialising nodes ie they're responsible for sending transaction requests to the network.
pBFT consensus occurs in three phases
a) pre-prepare phase: which occurs at the primary node. the node receives and verifies client requests and generates corresponding pre-prepare messages which they broadcast to all replica nodes.
b) prepare phase: during which replica nodes verify the legitimacy of received pre-prepare messages and broadcast corresponding prepare messages across other replica nodes and the primary node. When any one node gathers up to 2f+1 prepare messages, it broadcasts a commit message showing it is ready for block submission.
c) Commit phase: the nodes send commit messages to each other, when any one node gathers up to 2f+1 commit messages, it processes the original client request and updates the network to reflect this change.
These phases must be completed within a specified time limit or else the data is rejected and the network maintains its original state. If this occurs, a "view-change" protocol is triggered to re-evaluate the submitted data-set and try to achieve consensus again.
The view change protocol ensures that the network is kept active and safe ie it ensures network liveness.
Proof of Stake was initially proposed in 2011 by the bitcoin community as an energy efficient alternative for proof of work. The stake refers to the network's tokens owned by a participant which is delegated to the consensus process and locked up in a smart contract. This system leverages token ownership for Sybil attack mitigation while moving opportunity cost from outside the network (computational power loss) to within the system (capital loss). PoS protocols are somewhat similar to PoR protocols in that they require “proofs”, in the former case, proof of dedication to the success of a blockchain by possession of its native token locked up in a smart contract and often earning interest
PoS protocols are currently mostly implemented in tandem with one of the other protocols for finalisation.
• PoS-PoW protocols are implemented such that epoch leaders are selected via hash puzzles whose computation ease depend on the stake value of a node hence preventing brute-force hashing competitions. The solution to the puzzle is also attached to the mined block during propagation to enable validation.
In another iteration, a committee of stakeholders who are selected due to their respective stakes in the network are allowed to produce blocks in cycles. A secure multiparty computation scheme is used to generate such committees such that nodes with higher stake values are likely to take up more spots in the committee. A bottleneck in such protocols is the committee size. Large committees will likely lead to deterioration in network connectivity which results in poor protocol performance and desynchronisation of block proposal schemes as well as endless consensus cycles due to excessive communication overhead. Smaller committees ensure efficient consensus process but lead to centralisation. Block production is more orderly and they inherit the 50% network security threshold of the Nakamoto consensus
• PoS-BFT protocols wherein epoch leaders are often selected from a relatively fixed set of validators who achieve consensus via BFT standards. Checkpointing mechanisms are also implemented hence providing deterministic finality by "sealing" the blockchain at specified instants. Such protocols make use of the "most-recent-stable" checkpoint rule to determine the stable main chain and minimise/resolve forks.
PoS-BFT protocols usually have a 33% (⅓) fault tolerance threshold due to their inheritance of the BFT-style block finalisation, this is also often augmented by the block proposal scheme or preestablished identity schemes for validating nodes.
Congrats on making it this far, here's a complementary poap bunny courtesy of DS🤝

You've probably noticed already but the previous consensus implementations are mostly for blockchains. Consensus is still a major issue in DAGs (bane of their existence imo) and is mostly theoretical at this point so MAYBE next time.
Hit the like button and share to gift nitro & adrenaline, comment and criticise to gift knowledge and subscribe for more bunnies & word salad, tysm. Any mistakes/misconceptions are mine alone as this wasn't proofread by industry specialists🧏.